A House Divided: Orgo vs. Ochem
The Question of our Time
In the summer of 2019, I was working with a bunch of students from across the country. One day, we all got on the conversation of organic chemistry and somehow we went on a long tangent of who calls that dreaded class “orgo” and who calls it “ochem”. At my undergraduate school, nestled firmly in the armpit of New Jersey, “orgo” haunted the dreams of many students (myself not included). By contrast, undergrads at Oregon State are beset by the monster known as “ochem”.
Naturally, the question must be asked: “Which schools call organic chemistry orgo and which call it ochem?”
The issue of course is asking someone from every school in the country - not only is it tedious, but it would require some facet of human interaction. Gross.
What’s easier is searching the subreddit of each school and seeing which term is more popular. The method I used to quantify the “popularity” of a term is the number of results that appear in a search for said term. Manual subreddit searching yielded some promising results, but of course I was looking for a way to have a computer do it for me.
Python Reddit API Wrapper
Enter the wonderful praw library.
With this python package, I can obtain all kinds of fun data, including the number of posts returned in a search.
I had found my in to get to the bottom of the question of our time.
I thought it might be neat to use praw to scrape the data I needed and to make a map of the United States detailing where this legendary “orgo”/”ochem” divide is.
Obtaining the Data
This data wrangling step consists of several data sources.
- Subreddit data was gathered from Karl Ding who has compiled sqlite database of universities around the world, their city and state, and their associated subreddit name
- I cloned their git repo and read their data into Python as a csv using the
pandaslibrary
- I cloned their git repo and read their data into Python as a csv using the
- Geographic data was gathered from The National Center for Education Statistics has an xlsx file containing the names of all institutions of higher learning in the United States, their address, and latitude and longitude coordinates
- I downloaded this .xlsx file, converted it to a .csv in Excel, then read it into Python
- Scraping data was obtained using the
prawPython library which is a wrapper for the Python Reddit API.- In order to scrape actual user data, I had to register a script application at the following website
The first two datasets are wrangled and merged in pandas without too much trouble.
The relevant columns from these two datasets are the name of the university, name of the subreddit, city, state, and lat-lon information.
To get the scraping data, I instantiated a praw.Reddit object using my Reddit credentials and a Python function to search for both “ochem” and “orgo” in each school subreddit.
reddit = praw.Reddit(client_id="cliend_id_I_used",
client_secret="client_secret_I_used",
password="my_password",
user_agent="my_user_agent",
username="my_username")
print(reddit.read_only)
reddit.read_only = True
print(reddit.user.me())This last line should print out your reddit user name. Of course I won’t be providing that here (what kind of maniac would publicly give out their reddit username?).
I then wrote a function which takes the name of a subreddit and a search string, then outputs the number of posts returned in a search of that subreddit.
def search_college_subreddit(subreddit, search_string, limit=1000):
output = len(list(reddit.subreddit(subreddit).search(search_string, limit = limit)))
return outputI looped over each school subreddit, executing my function each time and saving the results which I then joined back on to dataframe. My code looked something like this:
ochem_counts = []
for name, subreddit in zip(college_df['name'], college_df['subreddit']):
print("name: {}\nsubreddit: {}".format(name, subreddit))
try:
ochem_count = search_college_subreddit(subreddit=subreddit, search_string="ochem")
ochem_counts.append(ochem_count)
except:
print("Error with university {}".format(name))
ochem_counts.append(0)I then used pandas to create a final column organic_chemistry_name which put schools into one of 4 categories:
- “orgo” if the subreddit used “orgo” more than “ochem”
- “ochem” if the opposite,
- “tied” if the counts were equal
- and “no counts available” if the counts for both “ochem” and “orgo” were 0.
Let’s make a map
I am using R for this since it has a easy to use package usmaps for creating maps of the United States. In this section, I will present what data visualization that I used to answer the question of interest, and the final answer of those questions will be discussed in the next section as interpretation of the data.
library(usmap)
library(ggrepel)
data_to_plot <- final_df[,c("LON", "LAT", "name", "orgo_counts", "ochem_counts", "organic_chemistry_name")]
data_to_plot$total_chemistry <- data_to_plot$ochem_counts + data_to_plot$orgo_counts
data_to_plot$more_popular <- if_else(data_to_plot$total_chemistry >= data_to_plot$football_counts, "Chemistry", "Football")
data_transformed <- usmap_transform(data_to_plot)In the one final map where the points are colored according to the which slang term for organic chemistry is more popular. I also added a size aesthetic to capture how many total posts about chemistry the subreddit had.
The final ggplotcode will look something like this (note that I filtered out the “no counts available” category):
plot_usmap() +
geom_point(data_transformed, mapping = aes(x = LON.1, y = LAT.1),
size = .2) +
geom_point(subset(data_transformed, organic_chemistry_name != "no counts available"), mapping = aes(x = LON.1, y = LAT.1, color = organic_chemistry_name, size = total_chemistry),
alpha = .5) +
labs(title = "Name this class!",
subtitle = "Colored by what their subreddit calls Organic Chemistry",
color = "Organic Chemistry is...",
size = "Total Chemistry Posts") +
theme(legend.position = "right")And here it is, the long-awaited map of slang names for organic chemistry:
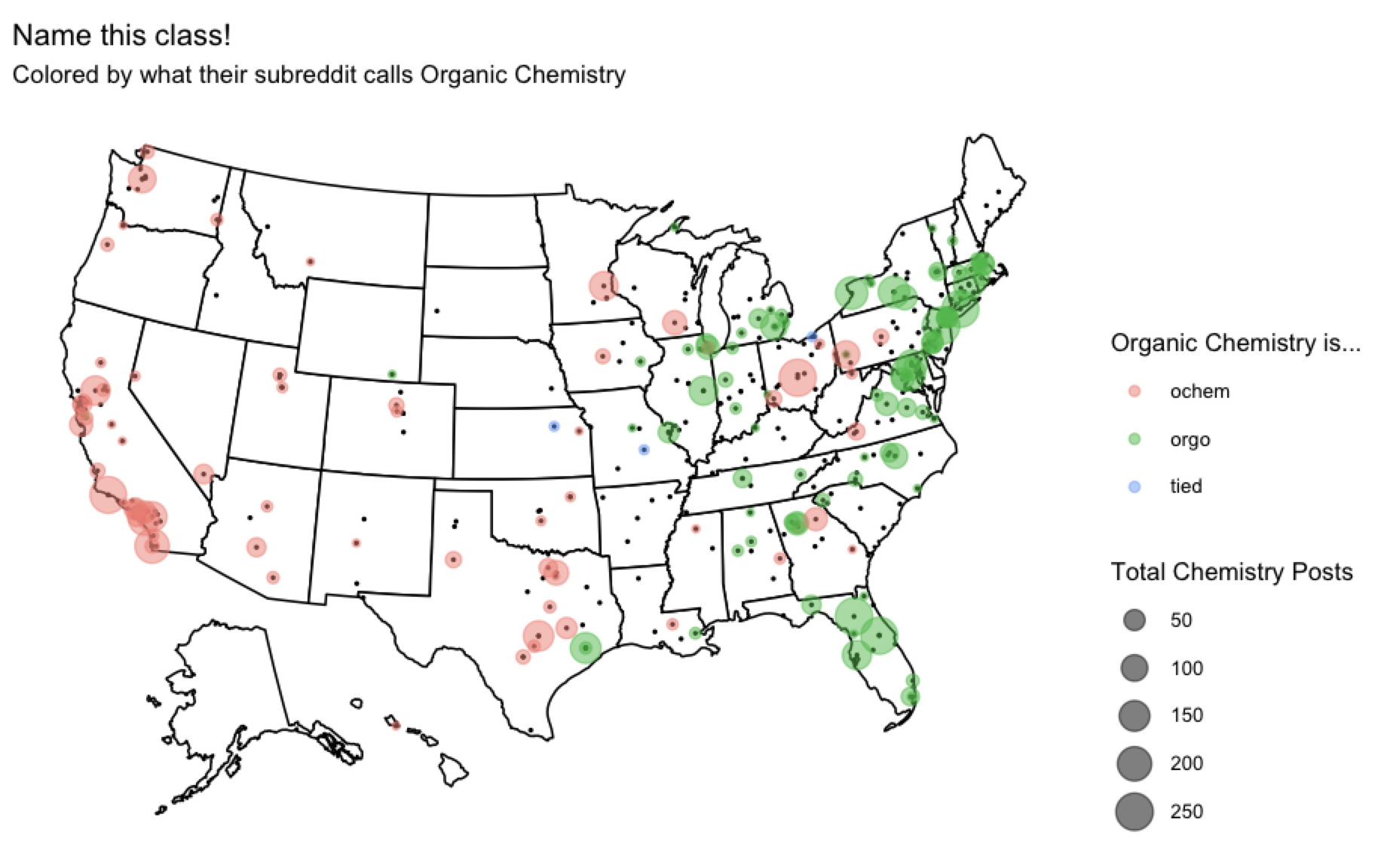
Interpret Data
So yeah, there’s generally an east-west split for “orgo” vs. “ochem” respectively.
I do think it’s interesting that the slang name for organic chemistry doesn’t have a clear divide. For instance, western Pennsylvania and Ohio keep the northeast from being solidly “orgo” while Florida keep the southeast US from being solidly “ochem”. Meanwhile, Rice University and University of Houston represent a weird “orgo” island in Texas.
For me, I gotta ask Georgians what’s going on with their state. Georgia Tech is firmly “orgo” and UGA belongs to the “ochem” camp, and both schools have somewhat significant sample sizes. I guess Clean, Old Fashioned Hate extends to more than just football.