Analyzing Reddit Comments with GCP and Spark
This quarter I signed up for a class called “Data Science Tools and Programming”. Thus far, the class has only been marginally useful – a lot of the topics are pretty beginner oriented (not that I’m a pro or anything, but I know enough Python and SQL to get by). For the final project though, we get to kind of cut loose and pick a topic that we are interested in, then try to answer questions we picked using tools we covered in class, namely Google Cloud Platform and Spark.
For my final project, I found a great repository of reddit comment and post information (courtesy of Jason at pushshift.io) that I decided to tackle in a VM instance.
I will be taking a month’s worth of Reddit comments and answering the following questions:
- What are the most active subreddits?
- Where should a redditor spend the most time if they want to maximize karma?
- Which subreddits are the most controversial?
This was my second real exposure to GCP, so I still have a lot to learn. The platform is broken into many different tools which perform different stages of the data analysis, from ingestion to storage to prep to analysis. The workflow that we used was this:
- Create a VM instance with sufficient disk storage to hold the unzipped json files
- Copy those json files from the instance to a Google Cloud Storage bucket.
- Prep the data using Dataprep
- Load the cleaned data into Google BigQuery to run a SQL
Creating a VM Instance and Getting the Data
Creating the GCP instance is pretty straightforward using the GCP console! As a student, I got $300 in free credits, which I naturally burned through pretty quickly throughout the term by leaving things on when I didn’t have to.
As of starting this final, I have $140 left which adds an element of drama and ~suspense~ to this final. What’s a data science assignment without some budgetary restrictions??
Now we can download the 15GB zipped file. I chose to download the most recent month available in September of 2019.
wget http://files.pushshift.io/reddit/comments/RC_2019-09.zst
A .zst file is a zip file in the Zstandard compression program (thanks Facebook).
In order to get at the goodness inside, we will have to download zstd.
Thankfully, this is pretty easy on an Ubuntu/Debian Instance.
sudo apt-get update
sudo apt-get install zstd
unzstd RC_2019-09.zst
The .zst file uncompressed is pretty huge! I had to try this part a few times with different instance disk sizes before I got it to work. Eventually, I found that creating an instance with a 200GB disk was enough. When unzipped, the file was 168GB.
One useful thing I learned is that the unzip utility can actually output the uncompressed size of a zipped file using the -l flag.
unzip -l yourzipfile.zip
Copying over to a GCS bucket
This part is pretty easy, but as you can imagine, pretty time-consuming. Essentially, GCP requires that we use a storage bucket as a staging area to hold data that we’ll analyze later with BigQuery and Spark.
I created a bucket using the Storage tab of the GCP console called cs512-reddit.
I can then copy over the big 168GB to this bucket using gsutil.
gsutil -m cp RC_2019-09 gs://cs512-reddit
Remembering the -m flag is important for huge files since this parallelizes the operation.
Additionally, if my file was instead a bunch of separate files, I would have to make sure that I moved these files into a single directory and then call cp on the directory.
This is because to load the data into later tools, we need to check individual files and there is no handy select all type button.
It is almost impossible to change files once they are in storage, so we need to do this in the instance before we move it into the bucket.
For me, copying this over to an instance with 2 cores and 8GB of RAM takes over an hour.
Dataprep
Dataprep (more specifically, Dataprep by Trifectra) is a preprocessing tool for large datasets that let’s you do tons of things, from filtering and selecting to parsing JSON data into columnar data.
For this project, I only needed to use basic selections to get the data I needed. From the original dataset, I only needed 6 columns.
Those columns were:
- Author (string)
- Body (free text)
- Subreddit (string)
- Score (numeric)
- Awards (Gold, Silver, Platinum, etc.)
- Controversiality (0 or 1)
Pyspark
Spark is a distributed computing system that is sort of based off of Apache Hadoop except instead of using a bunch of disk writes, it holds a bunch of stuff in memory (that’s all I pretty much know for now… still learning!)
I used Pyspark’s sql functions to run queries directly on a Google Compute Cluster to answer the first question.
I ran it using spark-submit --jars gs://spark-lib/bigquery/spark-bigquery-latest.jar reddit.py.
The pyspark script reddit.py that I submitted is provided below:
#!/usr/bin/python
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.master('yarn') \
.appName('final-reddit-analysis') \
.getOrCreate()
# Use the Cloud Storage bucket for temporary BigQuery export data used
# by the connector.
bucket = "reddit-temp"
spark.conf.set('temporaryGcsBucket', bucket)
# Load data from BigQuery.
comments = spark.read.format('bigquery') \
.option('table', 'final-reddit-analysis:reddit_comments.reddit_comments') \
.load()
comments.createOrReplaceTempView('comments')
# Perform word count.
comment_query = spark.sql(
'SELECT string_field_5 as sub, COUNT(string_field_1) as n_users FROM comments GROUP BY sub ORDER BY n_users DESC LIMIT 20'
)
comment_query.show()
comment_query.printSchema()Using this pyspark script, we got output directly in stdout.
BigQuery
For the other two questions, I used Google BigQuery against the preprocessed dataset.
I then exported the resulting tables and imported them into R.
I’m a real sucker for ggplot2 (matplotlib and seaborn… are not as good IMO).
The query to find the subreddits with the highest score is provided below. Note that BigQuery requires you to use a subquery in order to take output from GROUP BY statements and filter them.
SELECT sub, avg_score, comment_count
FROM (
SELECT string_field_5 as sub,
AVG(int64_field_4) as avg_score,
COUNT(string_field_1) as comment_count
FROM reddit_comments.reddit_comments
group by sub
)
WHERE comment_count > 1000
ORDER BY avg_score DESC, comment_count DESC
LIMIT 10The query for finding the most controversial subreddits is provided below. It follows similar logic to the above query.
SELECT sub, all_controversial/all_comments as prop_controversial, all_comments
FROM (
SELECT SUM(int64_field_3) as all_controversial,
COUNT(string_field_1) as all_comments,
string_field_5 as sub
FROM reddit_comments.reddit_comments
GROUP BY string_field_5
)
WHERE all_comments > 1000
ORDER BY prop_controversial DESCResults
- What are the most active subreddits?
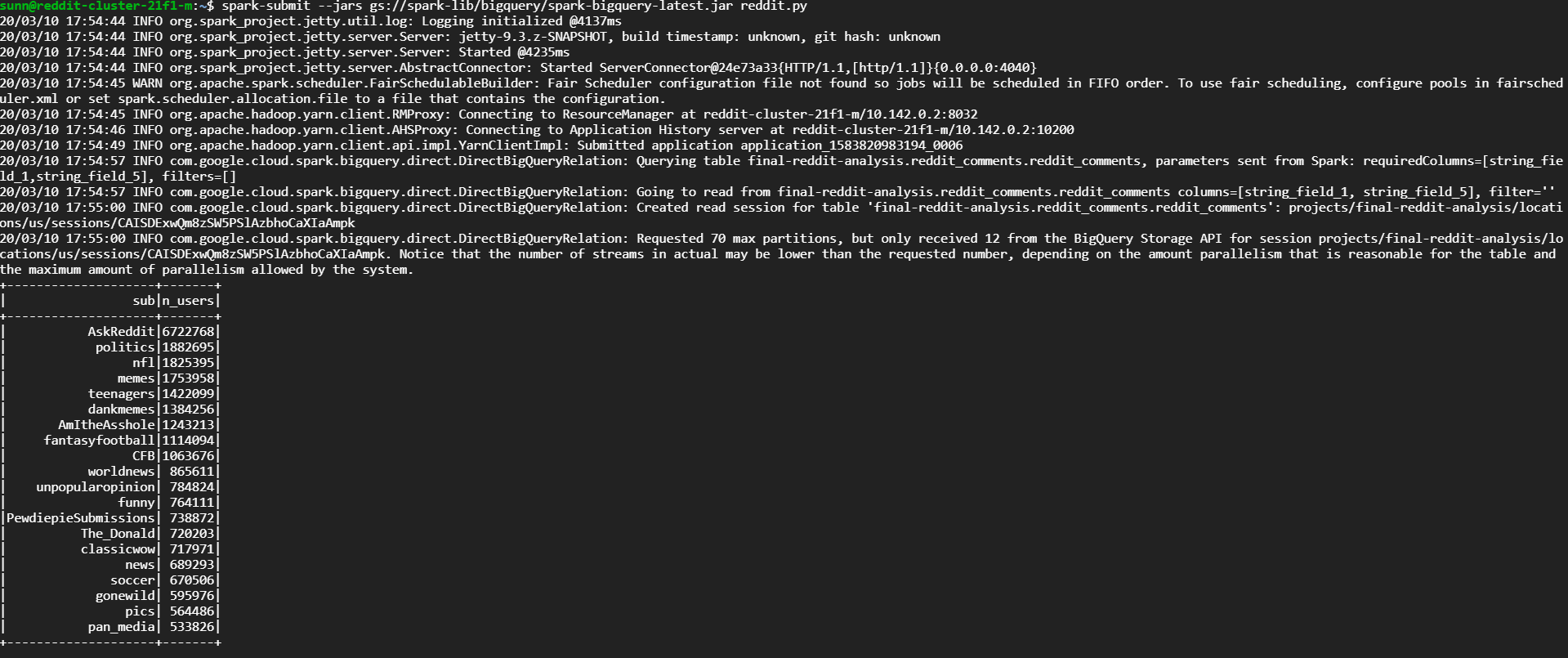
Not surprisingly, the most active subreddits are also the most popular subreddits!
Almost all of the top subreddits appear regularly in the front page of reddit r/all, and those that don’t are famous (or infamous) for having very active communities, for example, r/T_D which is a very controversial subreddit dedicated to Donald Trump and r/PewdiepieSubmissions which is a community based around the humor of popular youtube Pewdiepie.
- Where should a redditor spend the most time if they want to maximize karma?
This question is all about maximizing the karma (aka “worthless internet points”) a user can get by commenting in particular subreddits.
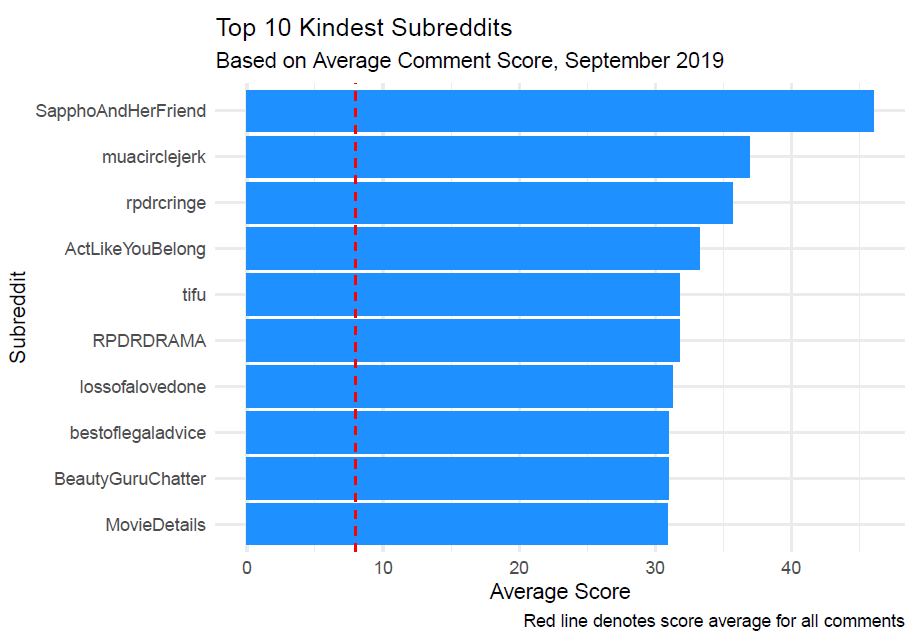
Interestingly, the kindest subreddits are communities centered around female or traditionally feminine topics.
For example r/SapphoAndHerFriend is a lesbian empowerment subreddit, r/muacirclejerk is for makeup, and any subreddit with rpdr involves RuPaul’s Drag Race (although as a fan, I can attest that the show doesn’t strictly cater to women).
Since this BigQuery job was inexpensive to run, I also decided to find the subreddits with the lowest average comment scores, modifying the ORDER BY clause.
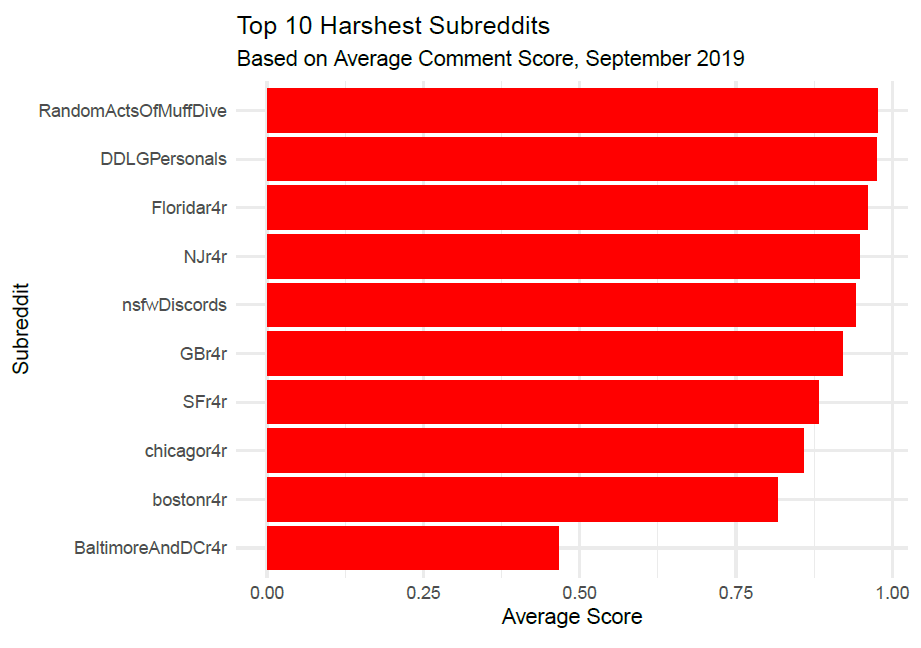
Less surprisingly, the subreddits with the lowest average scores are for the most part relatively mundane and elicit no strong feelings one way or the other.
Any subreddit that has r4r is about ridesharing and carpools in different cities.
The exceptions to this are some unpopular NSFW subreddits, which understandably might not engender strong positive reactions.
- Which subreddits are the most controversial?
This question focuses on computing the proportion of comments in a subreddit that are considered controversial. For a comment to be controversial, it has to have a large number of votes with a relatively equal balance of upvotes and downvotes.
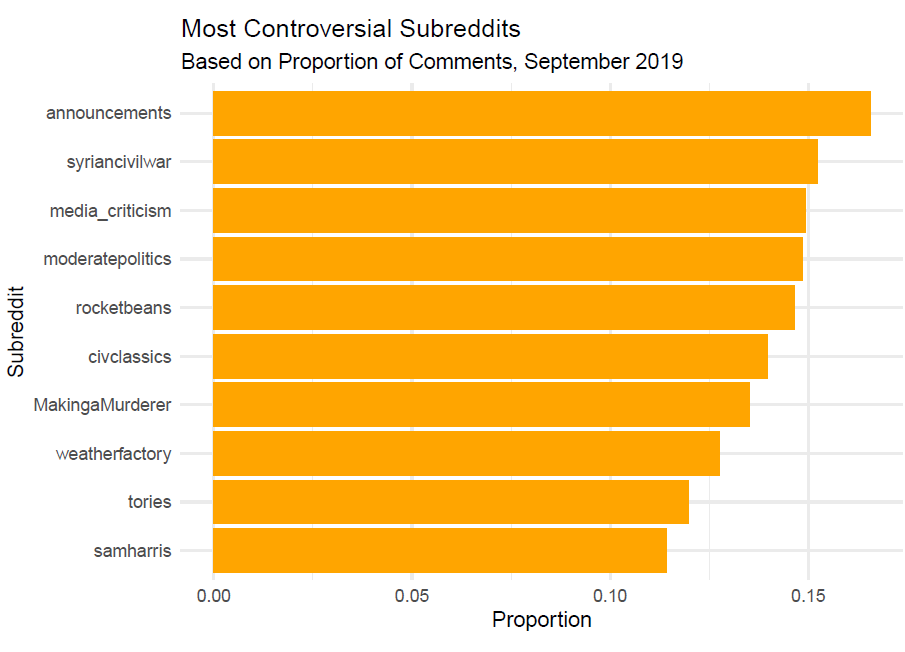
While some subreddits are not surprising given the subject matter e.g. the Syrian Civil War, criticism of mainstream media, politics, and Making a Murderer which is a docuseries about a man framed for murder, there are some surprising additions to this list.
For example, the most controversial subreddit is r/announcements which is a meta-subreddit about new features and changes to the website itself.
Video games also apparently represent controversial topics, for example, r/civclassics is about a Minecraft server, r/weatherfactory deals with a gaming company, and r/rocketbeans deals with German gaming youtubers.
Pushshift also has data dumps of reddit posts that would be interesting to join with this comments dataset, and future analyses could be done like regression modelling average comment score to post score.